
From Failure to Fix: A Practical Guide to COE Documentation and Lessons Learned
A Comprehensive Guide to COE Documentation

Introduction
In the software industry, documentation plays a crucial role in ensuring that processes are transparent, errors are minimized, and knowledge is shared effectively among team members. One of the essential documents in this context is the Cause of Error (COE) document.
This guide will help you understand COE documentation, how to interpret it, and what lessons can be learned from it. We’ll also provide a real-world example of a system failure and a sample COE document, including an event timeline to enhance clarity.
What is a COE Document?
A Cause of Error (COE) document is a structured report that provides a detailed analysis of a specific system failure or error. It goes beyond simply stating what went wrong, diving deep into the root causes, impact assessment, and corrective actions. COE documents serve several crucial purposes:
Incident Documentation: Providing a clear record of what happened, when, and why.
Root Cause Analysis: Identifying the underlying factors that led to the failure.
Impact Assessment: Quantifying the effects on users, business operations, and system performance.
Corrective Action Planning: Outlining steps to prevent similar incidents in the future.
Knowledge Sharing: Enabling teams to learn from past incidents and improve system resilience.
Example COE Document: XYZ System Outage
System Overview
The XYZ Financial Transactions Processing System is a critical component of global financial infrastructure, handling over 5 million transactions daily across 50 countries. It's responsible for processing various types of financial transactions, including credit card payments, wire transfers, and cryptocurrency exchanges. The system is built on a microservices architecture, utilizing a mix of cloud-native technologies and traditional database systems to ensure high availability and low latency.
The system typically handles peak loads of up to 10,000 transactions per second during high-traffic periods, such as Black Friday or end-of-quarter financial closings. It's designed to automatically scale based on demand, utilizing a combination of containerized applications and serverless functions.
Given its critical nature, any downtime or performance degradation in the XYZ system can have significant financial and reputational impacts on both company and clients. Therefore, maintaining its reliability and efficiency is of utmost importance to the organization.
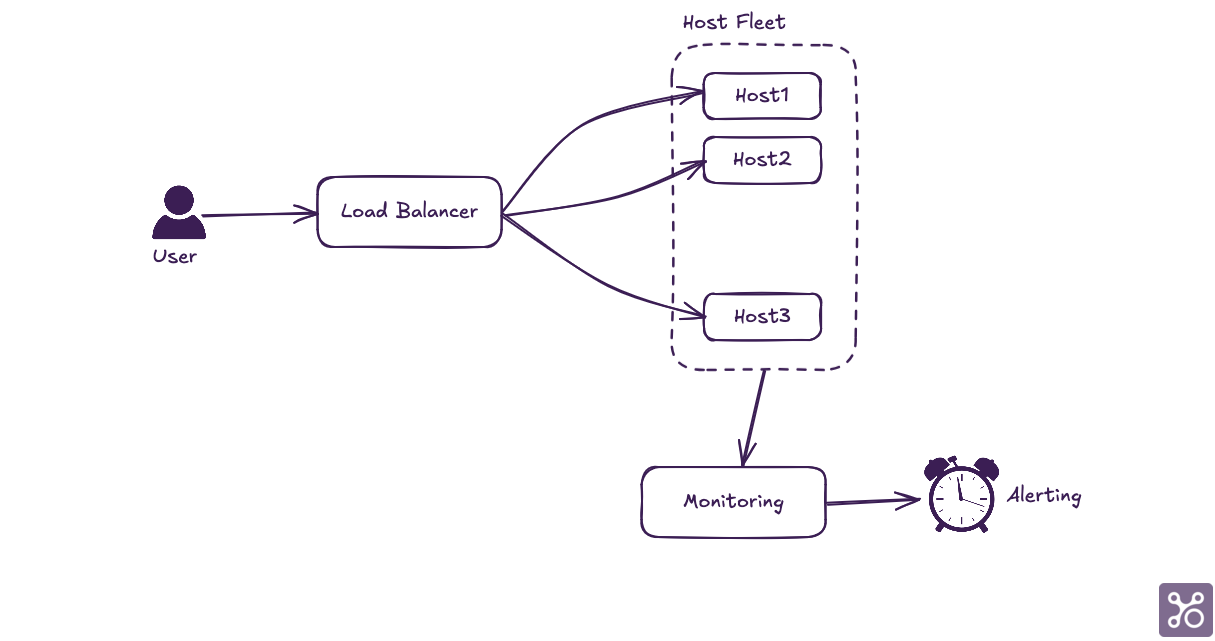
Now, let's examine a recent incident where this crucial system experienced a major outage:
COE Report
Incident Summary
Date: January 25, 2024
Duration: 02:00 AM – 06:30 AM UTC (4 hours 30 minutes)
Affected System: XYZ Financial Transactions Processing System
Reported By: System Monitoring Team
Detailed Event Timeline
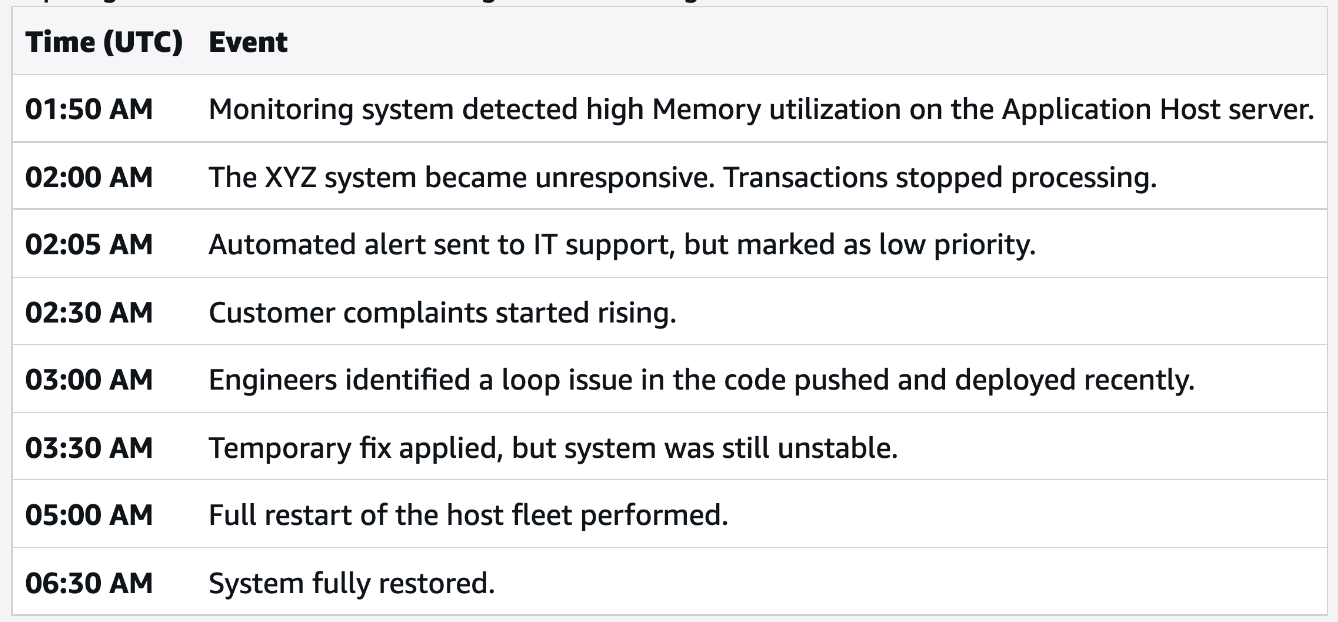
Impact Analysis
Financial Impact:
Estimated revenue loss: $500,000 due to failed transactions
Potential penalty fees: $50,000 for SLA breaches
User Impact:
100,000+ transactions disrupted
3,000+ support tickets opened
Operational Impact:
4 hours of complete system downtime
6 team members involved in incident resolution
Customer Satisfaction Metrics:
Net Promoter Score (NPS) dropped from +45 to +20
Customer Satisfaction (CSAT) score decreased from 4.5 to 3.2
👉 Why This Matters? This section quantifies the severity of the issue, ensuring management and technical teams understand the real-world consequences.
Root Cause Analysis
The primary cause of the system outage was insufficient memory allocation to the hosts running the XYZ system. Specifically:
Memory Leak: A recent code deployment introduced a memory leak in the transaction processing module.
Inadequate Monitoring: Existing monitoring thresholds for memory usage were set too high, delaying alerts.
Inefficient Resource Management: The system lacked automatic scaling or load balancing mechanisms to handle increased memory demands.
👉 Key Takeaway: Proactive monitoring and better alert prioritization could have prevented this incident.
5 Whys Analysis
Why did the XYZ system go down?
The hosts running the system ran out of memory.
Why did the hosts run out of memory?
A memory leak in the transaction processing module consumed available memory.
Why wasn't the memory leak detected earlier?
Monitoring thresholds for memory usage were set too high, delaying alerts.
Why were the monitoring thresholds set inappropriately?
The thresholds hadn't been reviewed or updated since the system's initial deployment.
Why wasn't the system able to handle the increased memory demand?
The system lacked automatic scaling or load balancing mechanisms.
👉 Note : Sometime team covers 5Whys as part of the root cause analysis.
Corrective Actions
Based on the root cause analysis, following corrective actions have been identified:

👉 How This Helps? This section ensures clear ownership and accountability for future improvements.
Lessons Learned
Monitor, Don’t Ignore! - Automated alerts should always be taken seriously.
Build Resilience - Auto-scaling and failover mechanisms must be implemented.
Rapid Response is Key - Faster identification could have reduced downtime by 50%.
Optimize Continuously - Regular performance reviews of queries and infrastructure are essential.
👉 Why This Matters? This section ensures that mistakes turn into learning opportunities, improving long-term system stability.
How to Read a COE Document Effectively
Understand the Document Structure: Familiarize yourself with the key sections of the COE document, including Incident Description, Impact Analysis, Root Cause Analysis, Corrective Actions, and Lessons Learned.
Start with the Incident Summary: Quickly grasp the overview of what happened, when it occurred, and its overall impact.
Analyze the Timeline: Study the sequence of events to identify critical points where intervention could have mitigated the issue.
Focus on Impact Analysis: Quantify the real-world consequences to understand the severity of the incident.
Dive into Root Cause Analysis: Look beyond the immediate cause to understand the underlying issues that led to the incident.
Evaluate Corrective Actions: Assess whether the proposed solutions adequately address the root causes and are sufficient to prevent future occurrences.
Reflect on Lessons Learned: Consider how these insights can be applied to other systems or processes in your organization.
Look for Patterns: If you have access to multiple COE documents, try to identify recurring themes or vulnerabilities across incidents.
Conclusion
COE documentation is an invaluable in the software development lifecycle. It transforms system failures from mere setbacks into opportunities for growth and improvement. By thoroughly documenting incidents, analyzing their causes, and implementing targeted corrective actions, organizations can:
Enhance system reliability and performance
Improve incident response times and effectiveness
Foster a culture of continuous learning and improvement
Strengthen customer trust through transparent communication
As the complexity of software systems continues to grow, the importance of comprehensive COE documentation cannot be overstated. It serves not only as a record of past incidents but as a roadmap for building more resilient, efficient, and reliable systems in the future.
By embracing the insights provided by COE documents, software teams can:
Stay ahead of potential issues
Optimize their processes
Deliver higher quality products to their users
Build a culture of accountability and continuous improvement
Remember, in the world of software development, every error is an opportunity to learn and improve. By diligently creating, analyzing, and acting upon COE documents, organizations can turn challenges into stepping stones for excellence.